I’m the teaching assistant for MATH116 this semester and the office hours I originally chose didn’t suit most of my students. To remedy this, I set up a doodle poll asking them which times they could do. I downloaded their responses as an Excel table and exported it .csv (comma-separated values).
Tag: haskell
I repeat
There’s less than two weeks left before exams, trials more difficult than anything I’ve ever had to face. I find myself in a destructive loop of procrastination and anxiety. Today was a pleasant day spent revising Principles of Programming Languages. Well, it was spent coding something that was more exciting than preparing for exams.
Becoming a Champion
My girlfriend’s father enjoys a casual game of Bubble Breaker, he even got into the top 100 players on the website he frequents. Trying to impress/troll him lead me to the following challenge: become the Bubble Breaker champion.


Bubble Breaker
Rules: pop a connected set [blob] of bubbles (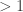
Goal: remove 
Utility:
- popping a blob of size
:
- removing
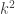

Termination: the game ends when the goal is reached or when there are no blobs of size
Cheating
Well, as I didn’t want to spend a lot of my time playing Bubble Breaker there was an obvious plan: write a program that plays it for me. To make things a lot easier I asked a more experienced programmer, exFalso to help.

Components
Sensor: a scraper that runs the java applet and collects the data necessary for the controller
Controller: a (limited) depth-first search in the graph of game states armed with awesome heuristics
Actuator: play the game (in the applet) according to the „best” sequence of moves found by the actuator
As for heuristics we planned introduce a number of variables regarding the game state and see how they correlated with high scores.
Moar Cheating
While I was working on the controller, exFalso started working on the sensor. He wanted to use Javascript to get the applet’s position but I thought it would be a better idea to trick the applet into running outside of the browser.
This required exFalso to decompile the applet. The result was shocking: the decompiled code had sensible variable names and was well-formatted. After writing a Swing container for the applet exFalso realised something that would change everything: despite the fact that the applet interacted with the server on each move, it was possible to send an arbitrary high score without playing.
A note on premature optimisation
Prior to discovering that we could “print our own money” we spent a lot of time arguing about the controller: I thought it should be written in Haskell (rather unsurprisingly) and he pushed C++. His argument was that depth-first search was inherently stateful (as well as the whole algorithm) and that mutable linked lists are part of the obvious solution. Even after I convinced myself that this was rubbish, I still spent a lot of time thinking about the difference between using immutable arrays or lists of lists for the representation of the grid.
I think this is a rather striking example of premature optimisation: when you optimise code that won’t even be used in the final “product”.
Finally I’d like to thank Alex and Pete for their advice.
Numbering a tree
Sometimes I feel a sudden urge to perform effectful computations on binary trees. Or maybe I just want to number the values in the tree! Let’s consider two types of numbering. (Images depict a tree followed by the same tree with values replaced by their number in the ordering)
Depth-First order

Infix order

It would be nice to somehow use the natural fold function on this data structure given by:
foldTree f g (Leaf a) = f a
foldTree f g (Branch a t1 t2) = g a (foldTree f g t1) (foldTree f g t2)
But there is a problem: for some traversals t1 should be folded before t2 or the other way round. Why is this a problem? Because this fold currently has no notion of time and we can’t really specify which ‘sub-fold’ we want to happen first!
A simple solution consists rewriting foldTree to work on (Tree a, Integer) tuples, where the integer is the offset at which the numbering should start. This offset can then be passed down, and back up recursively! I originally used this, then I thought: well, there’s no point of reinventing the State monad.
So tuples were removed and I could also make use of foldTree [edit: I just failed pretty hard at embedding code, see link at the bottom]
Almost the same thing can be done for depth-first numbering. But there are other types of orderings of trees, what happens if you need to reverse the order? There is an elegant solution using the backwards state monad. How about Breadth-First ordering? Well that can’t really be done using this type of technique, once I figure out how delimited continuations work, I’ll make sure to write a post about it…
Conclusion
The solution works, but is not particularly beautiful, and basically defines a new type of fold, but in a less readable manner. Click here for the complete code incl. infix, depth-first and example
Untyped Lambda Calculus “Implementation”
So, I started reading TAPL and it seemed like a reasonable and quick exercise to implement the untyped lambda calculus in Haskell. I was trying to make my implementation use strict evaluation as the book uses that as well, but I ran into a number of problems.
Environment
I didn’t want to make a big fuss about environments and scope, so basically they are not implemented any further than this:
f = something
where g = something else
turns into
(\g -> something) (something else)
Unfortunately with this model, if there is a non-terminating term in the environment (say omega) then the whole reduction becomes non-terminating.
If
The if-then-else control structure is typically implemented in the following way:
b v w
where b is either t (k) or f. The obvious problem here is: both v and w have to be reduced in order to reduce the expression, therefore recursive definitions will never terminate! This explains why there are no programming languages that do this.
Conclusion
Strict, untyped lambda calculus is problematic.
If … then … else …?
It’s the 1790s and we’re in the middle of the French Revolution. Nobody really know what they want, but they know what they don’t want: l’ancien regime! So the Replubic decides to do all it can to revolutionise; reinvent the calendar, advocate our beloved metric system, etc.

And the 18th century functional programmers (all of them) thought that they should change a few things about Haskell’s syntax, make it more modern, more French! So the first change they proposed was getting rid of those overly English if then else statements. But as they didn’t know too much about compilers, they decided to solve this problem inside Haskell itself.
The first thing they tried was the lambda calculus-esque
si :: Bool -> a -> a -> a
si True a b = a
si False a b = b
But this wasn’t good enough! The infix version was simply nicer to look at! So after a lot of thinking, they came up with a version that used continuations:
si bool = \k -> k bool
alors True x = \k -> k $ Just x
alors False x = \k -> k Nothing
sinon (Just x) y = \k -> x
sinon Nothing y = \k -> y
merci = id
This would be used as:
si (a `isMoreGuiltyThan` b)
alors (map guillotine [a, b])
sinon (map guillotine [b, a])
merci
Note: this code would’ve had side-effects!
Update:
The code above did not satisfy the National Convention, so it was upgraded to the nicer:
si bool = \k x y -> k bool x y
alors True z = \k x -> k z
alors False z = \k x -> k x
sinon x = \k -> k x
merci = id
Guillotining (usage) as before!
How not to approximate pi
So, a question on one of last year’s analysis sheets is concerned with the the limit of | sin (n+1) / sin (n) |. I had a feeling it would be unbounded but decided not to think too hard about it, and play with Haskell instead:
Prelude> let f x = abs (sin (x+1) / sin x)
Prelude> let n = 100000 in snd . maximum . map (\x -> (f x,x)) $ [1..n]
355 is the answer it gives, but why? It is because 355 is the integer closest to any multiple of pi (in the 1..100000 range), thus the denominator of the fraction will be close to 0. As n increases it is easy to see that there will always be a number which is closer to a multiple of pi, then any previous one, therefore the denominator gets arbitrarily close to 0, hence the sequence is unbounded. (Nominator goes to sin 1 != 0…)
Kind of pointless, but it was nice to see how good an approximation 355/113 is!
My very own theorem prover :: Type -> Lambda
I was reading up on type theory when I ran into the Curry-Howard isomorphism.
“So we meet again”, I said. “I have failed to understand you in the past when we first met on that wikibook. I had no idea what intuitionistic logic was and didn’t know too much about lambda calculus either. This is still the case, but I know just enough to be able to implement you in Haskell.”
And so, here it is.
Missing features
- disjunction (not very exciting in lambda calc)
- quantifiers
- μ (mu) operator to create (and handle?) recursive types
- interface (try
prove compose,prove bug1, some test cases at the eof)
My first language implementation, Counter
So I spent the last 3 days working on an implementation for a language that is similar to a model of computation described in Harel’s book on Algrorithms. The language is very primitive, it can only add, negate, assign, print and perform jumps with one type of condition (<).
Here’s some code
x = -5
x > 0: positive
x = -x
#positive
x
This simple code demonstrates every feature of the language.
I wrote the parser and interpreter in Haskell and I’ve got monads (and transformers) pouring out my ears now. I think I’m going to avoid them for a while…
I asked for some help on Haskell IRC when I was struggling to write the recursive bit of the parser (for expressions like 4+5+6) and dafis gave me some code that (almost) parsed expressions right-recursively ie. 4+5+6 -> (4+(5+6)). This give rise to the following question: is it possible to write a left-recursive parser using StateT String Maybe a? I don’t know. Yet.
Click for the code (and sample Counter programs: slow.co, mult.co)
Models of Computation
I recently started an implementation of (finite) automata in Haskell and it turned out to have fundamental similarities with this library (but that of course is much better developed.
I tried to treat deterministic and non-deterministic automata similarly without creating a typeclass, this lead to using Monads and Foldables. The goal would be to be able to freely convert
- NFA to DFA
- RegExp to NFA
- DFA, NFA to Graphs (using GraphViz)
Nothing really works at the moment, most functions were written with DFAs in mind, and I’m not sure how to realise ε-transitions…
Stay tuned!
